Proof from the product
Real UI snapshot used to anchor the operational workflow described in this article.
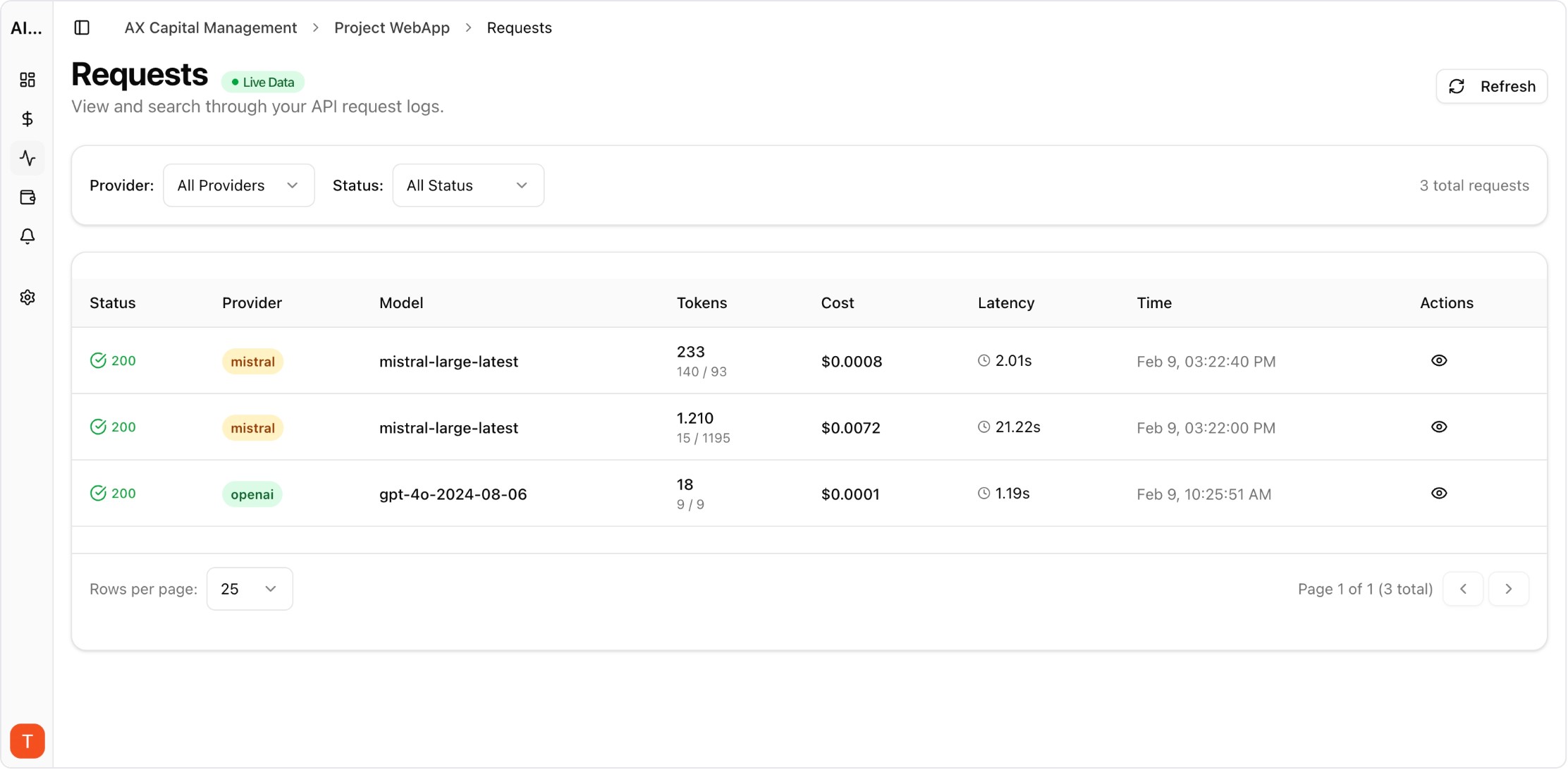
AI cost overruns rarely happen as a single obvious event. They emerge through small shifts in traffic, prompts, and retry behavior that compound over days. This playbook helps teams detect and contain anomalies before invoices force reactive cuts.
Real UI snapshot used to anchor the operational workflow described in this article.
Baseline spend by project, endpoint, and provider. Global totals can hide local incidents where one feature doubles cost while overall volume stays flat.
Use dual conditions: percent change over baseline and hard spend ceilings. This catches both gradual drifts and sudden spikes caused by rollout or provider incidents.
Link spend signals with timeout and retry patterns. Many anomalies are reliability events in disguise, and correlation shortens investigation time.
Incident responders need instant filters for model, provider, project, and environment. Drill-down views reduce handoff delays across platform and product teams.
Containment can include model downgrades, retry cap reductions, or temporary endpoint limits. Predefined actions remove debate during high-pressure incidents.
After each anomaly, record root cause, detection lag, and financial impact. Use lessons learned to improve thresholds, routing policies, and release checklists.
AI Observability Stack for SaaS Teams: What to Measure Beyond Tokens and Spend
observability · framework
Multi-Provider LLM Strategy: How to Reduce Risk and Improve Uptime in Production
provider-strategy · how-to
LLM Observability for Agency Workspaces: Multi-Client Monitoring That Scales
observability · commercial
AI SLA Monitoring with Latency and Error Budgets for Production Teams
observability · problem
Anomaly detection is most effective when alerts are tied to clear runbooks. Budget Alerts and unified observability views give teams the speed needed to contain spend drift early.