Live pricing snapshot
Input / 1K
$0.0002
Prompt tokens
Output / 1K
$0.0006
Completion tokens
Input / 1M
$0.1500
Large-volume planning
Catalog models
144
Current pricing catalog size
gpt-4o mini cost
GPT-4o Mini request volume can scale faster than expected. Use this calculator page to estimate spend before overruns.
Model routing choices are easier when GPT-4o Mini cost is visible at request level.
Input / 1K
$0.0002
Prompt tokens
Output / 1K
$0.0006
Completion tokens
Input / 1M
$0.1500
Large-volume planning
Catalog models
144
Current pricing catalog size
Real UI snapshot from AI Cost Board used in production workflows.
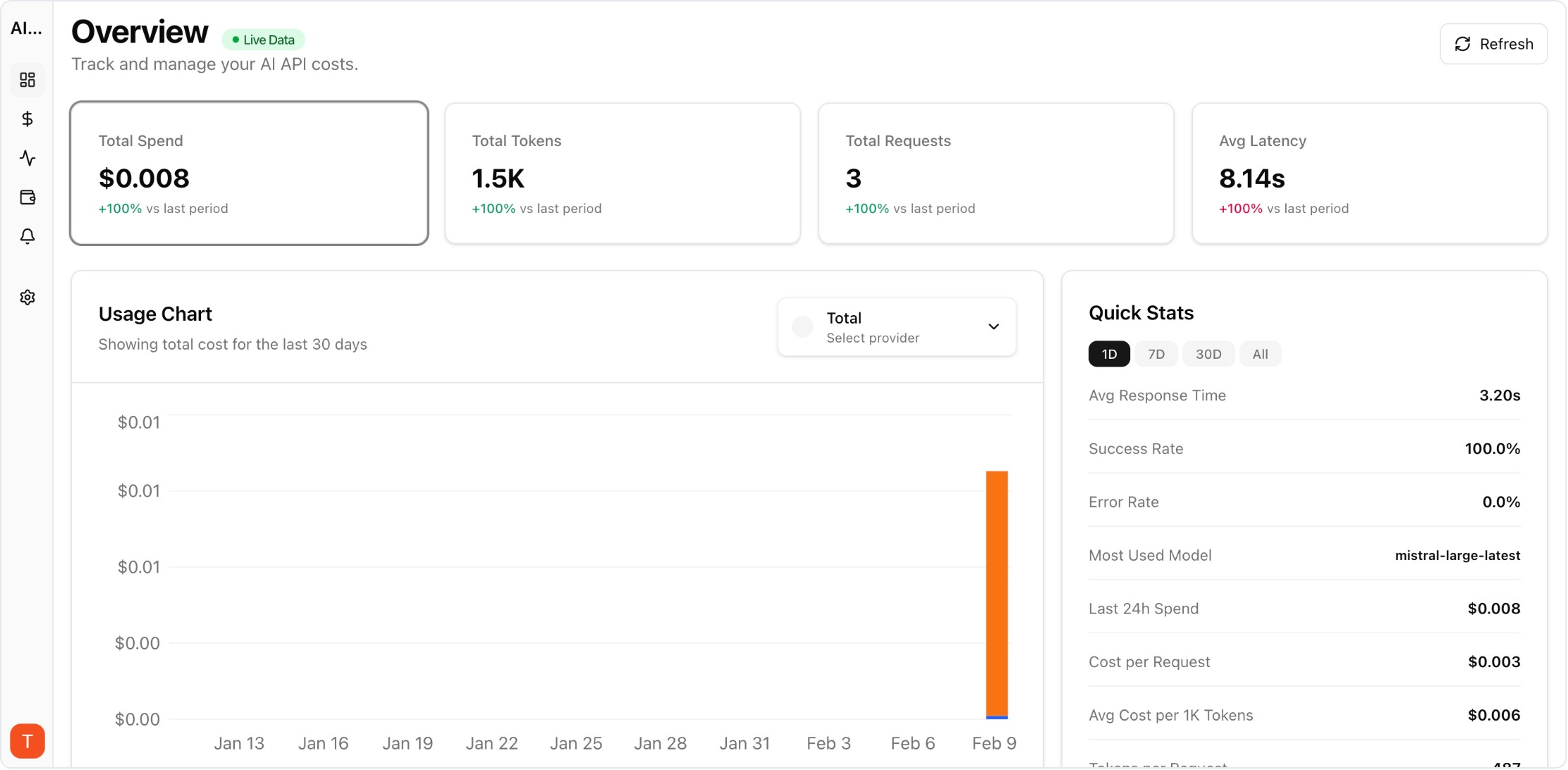
Provider-level drilldown for spend and token economics.
Estimated mode. Input capped at 100,000 chars.
Pricing updated: Jul 19, 2026, 05:00 AM
Input Cost
$0.0000
Output Cost
$0.000038
Total Cost
$0.000038
Price basis: 15 cents / 1M input tokens and 60 cents / 1M output tokens.
Use this free tool without login.
If you want ongoing tracking by project/provider, continue in the dashboard.
Normalize with the same prompt/output profile for every model. This page uses live input/output rates for OpenAI and converts them into per-1K and per-1M views.
Yes. Use the embedded calculator or pricing table first, then multiply by expected request volume and retry behavior.
Track retries, latency, and error rate. Production spend is pricing multiplied by operational behavior.
Use AI Cost Board to monitor cost per team, project, model, and provider with budget alerts and anomaly detection.
Move from one-off estimates to project-level cost, token, latency, and error tracking with alerts.
Start free tracking