Live benchmark snapshot
Input / 1K
$0.0300
Prompt tokens
Output / 1K
$0.0600
Completion tokens
Input / 1M
$30.0000
Large-volume planning
Catalog models
144
Current pricing catalog size
openai usage alerts
openai usage alerts pages attract high-intent evaluation traffic. This page combines live benchmarks with actionable workflow steps.
Turn this intent into an implementation plan: benchmark live pricing, model request cost, and set production alerts.
Input / 1K
$0.0300
Prompt tokens
Output / 1K
$0.0600
Completion tokens
Input / 1M
$30.0000
Large-volume planning
Catalog models
144
Current pricing catalog size
Real UI snapshot from AI Cost Board used in production workflows.
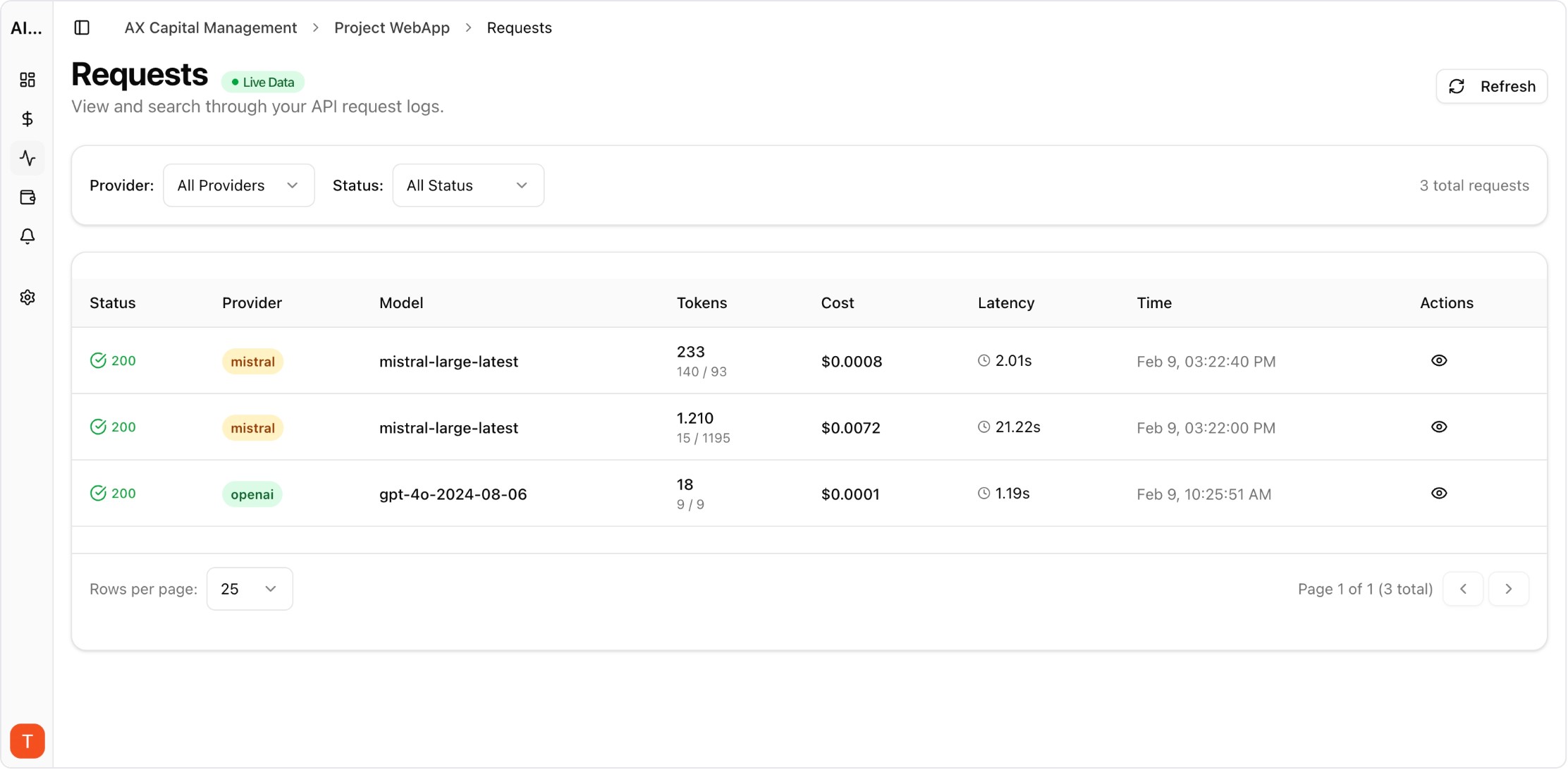
Budget and anomaly alerts to control runaway LLM spend.
Estimated mode. Input capped at 100,000 chars.
Pricing updated: Jul 19, 2026, 05:00 AM
Input Cost
$0.0000
Output Cost
$0.00384
Total Cost
$0.00384
Price basis: 3,000 cents / 1M input tokens and 6,000 cents / 1M output tokens.
Use this free tool without login.
If you want ongoing tracking by project/provider, continue in the dashboard.
Start with top cost drivers and implement one reduction lever per sprint.
Track cost per successful request and daily burn rate. This exposes high-impact optimization opportunities quickly.
It adds provider-level analytics and automated budget alerts.
Move from one-off estimates to project-level cost, token, latency, and error tracking with alerts.
Start free tracking