Proof from the product
Real UI snapshot used to anchor the operational workflow described in this article.
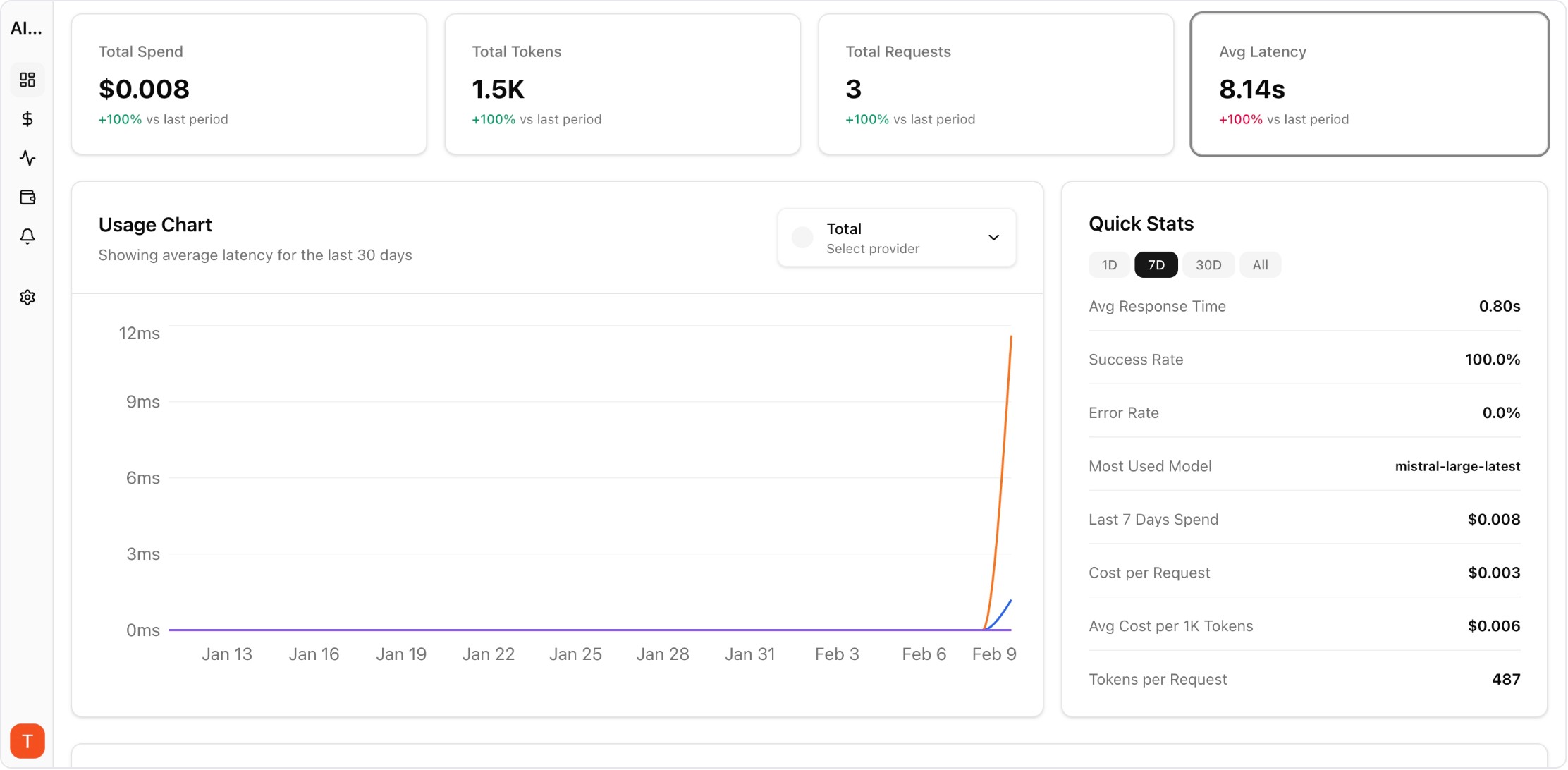
AI FinOps extends traditional cloud FinOps principles to AI and LLM workloads. As organizations scale from pilot AI projects to production systems, API costs can grow from hundreds to tens of thousands per month without visibility. AI FinOps provides the framework for cost governance, budget accountability, and spend optimization across all AI operations — turning unpredictable AI costs into managed, optimized investments.
Real UI snapshot used to anchor the operational workflow described in this article.
AI FinOps (Financial Operations for AI) is the practice of applying cost governance, accountability, and optimization to AI and LLM workloads. Unlike traditional cloud FinOps focused on compute and storage, AI FinOps addresses unique challenges: per-token pricing, model selection cost impact, prompt engineering economics, and multi-provider cost optimization. With LLM API costs often representing the fastest-growing line item in engineering budgets, AI FinOps is becoming essential.
Cloud FinOps manages infrastructure costs (compute, storage, networking) that scale predictably. AI FinOps manages API costs that scale with usage patterns, prompt length, model choice, and output quality. A single prompt engineering change can 10x costs. Model upgrades can double per-request spend. AI FinOps requires real-time visibility because costs accumulate at API-call speed, not monthly billing cycle speed.
AI FinOps rests on four pillars: (1) Visibility — real-time cost tracking per model, project, and team. (2) Governance — budget alerts, approval workflows, and spending limits. (3) Optimization — model selection, prompt engineering, caching, and routing for cost efficiency. (4) Accountability — cost attribution per project, team, and business function with finance-ready reporting.
Start with visibility: connect all AI API keys to a monitoring platform like AI Cost Board. Next, establish governance: set budget alerts and per-project spending limits. Then optimize: review model selection (do all tasks need GPT-4?), implement caching for repeated queries, and optimize prompt length. Finally, build accountability: create cost attribution by team and project, generate regular cost reports for stakeholders.
A complete AI FinOps stack includes: (1) Cost monitoring — AI Cost Board for real-time spend tracking across providers. (2) Budget controls — alerting and limits to prevent overspending. (3) Analytics — per-model, per-project cost breakdowns. (4) Reporting — finance-ready dashboards for stakeholder communication. (5) Optimization recommendations — insights on model selection and cost efficiency opportunities.
Common cost reduction strategies: Route simple tasks to cheaper models (GPT-4o-mini instead of GPT-4o). Implement semantic caching for repeated queries (5-15% savings). Optimize prompt length (shorter prompts = lower costs). Use batch APIs for non-real-time workloads (50% savings with OpenAI batch). Set anomaly detection to catch cost spikes early. Review unused or underperforming AI features regularly.
LLM Cost Optimization Guide: 11 Tactics to Reduce AI Spend Without Losing Quality
cost-optimization · framework
AI Observability Stack for SaaS Teams: What to Measure Beyond Tokens and Spend
observability · framework
LLM Cost per Support Ticket: How to Track and Lower AI Service Margins
cost-optimization · commercial
AI Feature Unit Economics Framework for SaaS and Agency Teams
cost-optimization · framework
AI FinOps is not optional — it is the difference between AI projects that scale sustainably and those that get killed for cost overruns. Start with visibility, add governance, then optimize continuously.