Problem
SaaS teams often see aggregate usage growth but miss which project, endpoint, or model change is driving cost and reliability risk.
Run LLM usage monitoring for SaaS with one workflow for usage, cost, reliability, and provider-level comparisons.
SaaS teams often see aggregate usage growth but miss which project, endpoint, or model change is driving cost and reliability risk.
| Area | What good looks like |
|---|---|
| Problem signal | SaaS teams often see aggregate usage growth but miss which project, endpoint, or model change is driving cost and reliability risk. |
| What to measure | Requests, tokens, cost, latency, errors, and provider/model breakdowns |
| Operational proof | Request logs + dashboards + alert history + project-level attribution |
| Decision loop | Weekly review with engineering and finance owners |
Real UI snapshot from AI Cost Board used in production workflows.
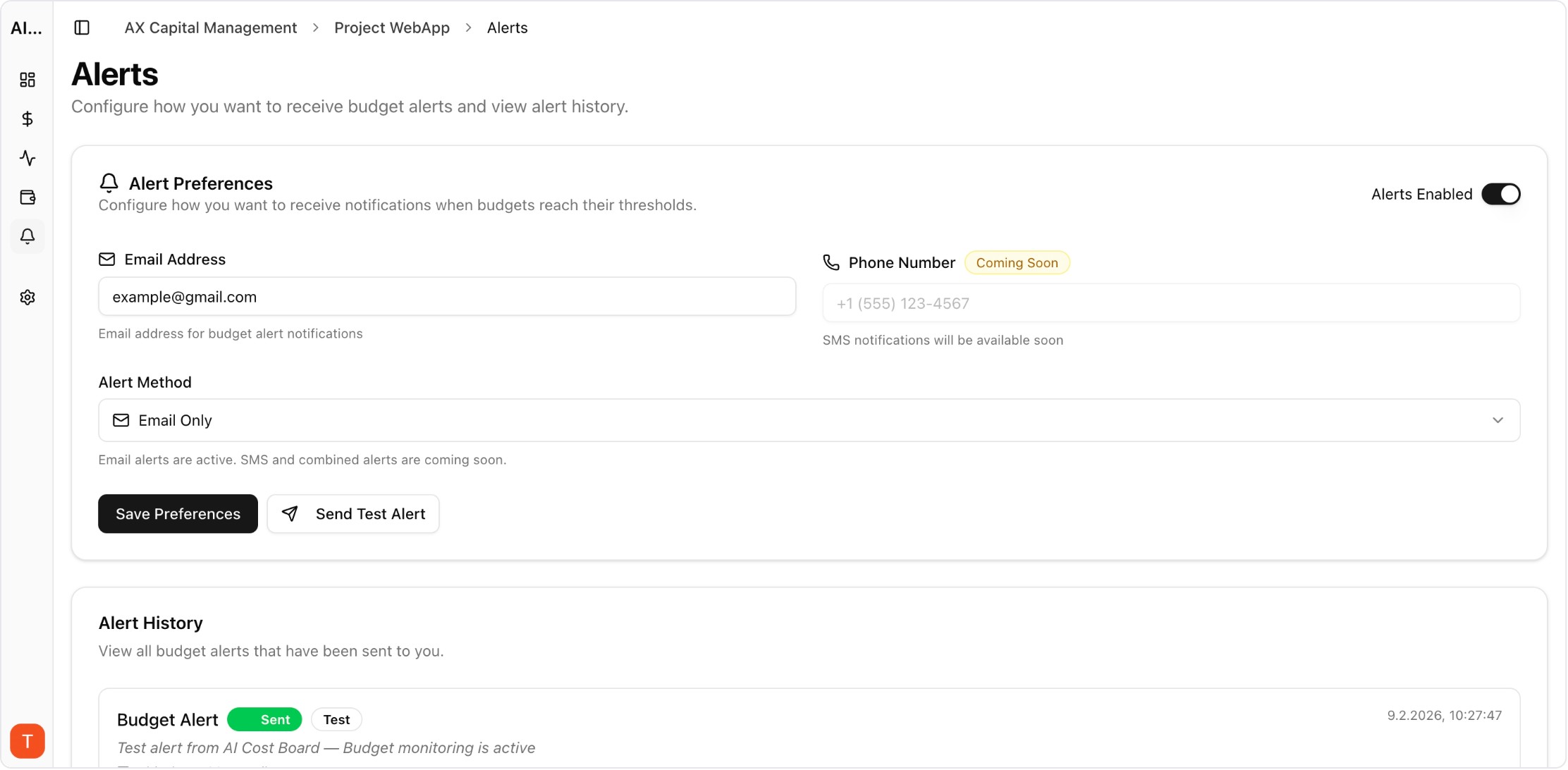
Usage, cost, latency, and error trends in one dashboard for SaaS teams.
Monitor cost, tokens, usage, latency, errors, and request logs across providers in one platform.
This page is for engineering, platform, finance, and product teams evaluating AI API observability and cost-control workflows.
No. It covers cost together with usage, latency, errors, and request-level evidence so teams can make safer production decisions.
Yes. AI Cost Board combines dashboards, request logs, provider analytics, and budget controls for this use case.