Problem
Anomaly detection fails when teams only watch daily cost totals and ignore request volume, retries, latency spikes, or provider-level degradations.
Detect AI API cost anomalies before they become invoice surprises by combining cost signals with operational telemetry.
Anomaly detection fails when teams only watch daily cost totals and ignore request volume, retries, latency spikes, or provider-level degradations.
| Area | What good looks like |
|---|---|
| Problem signal | Anomaly detection fails when teams only watch daily cost totals and ignore request volume, retries, latency spikes, or provider-level degradations. |
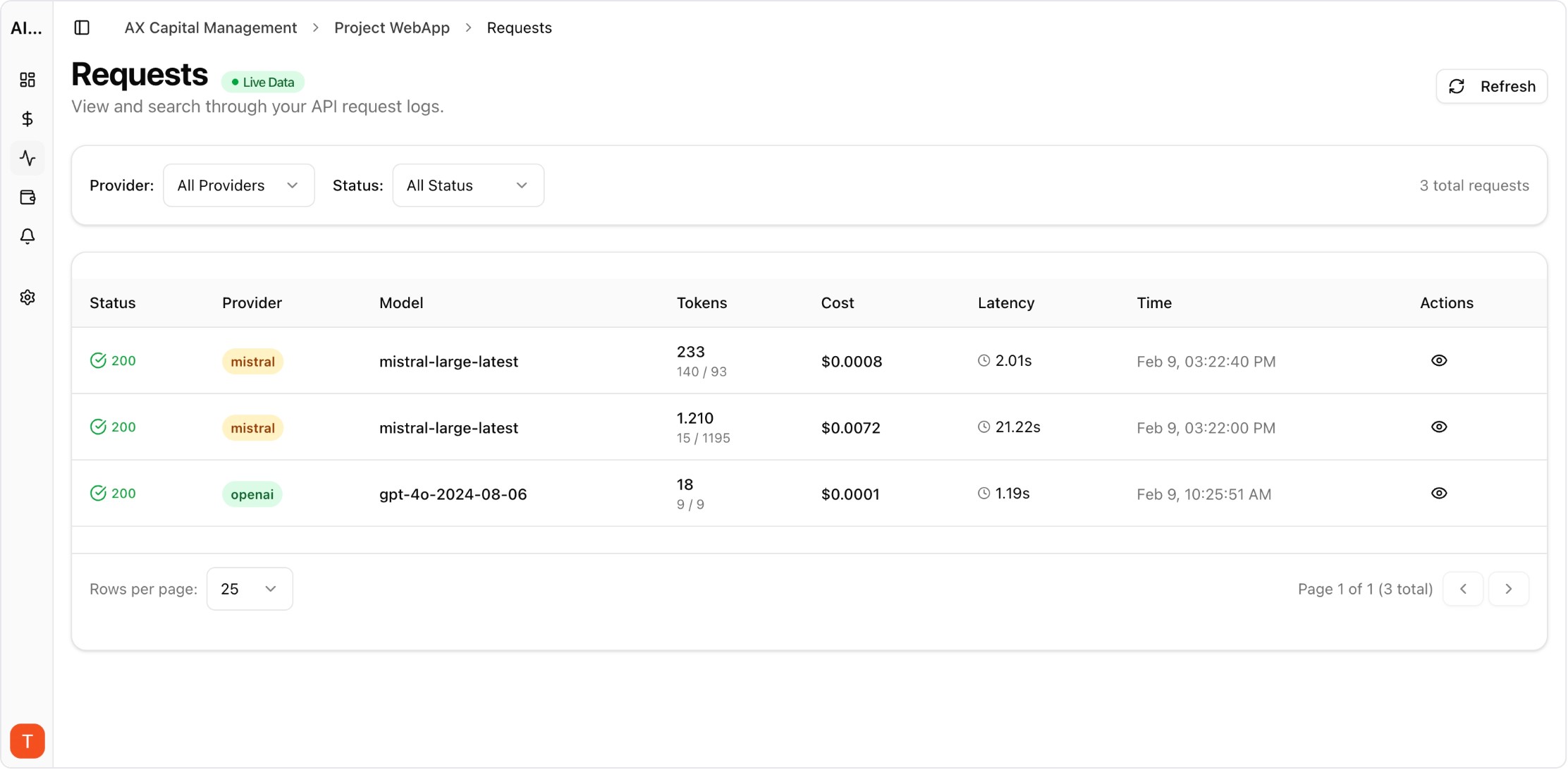
| What to measure | Requests, tokens, cost, latency, errors, and provider/model breakdowns |
| Operational proof | Request logs + dashboards + alert history + project-level attribution |
| Decision loop | Weekly review with engineering and finance owners |
Real UI snapshot from AI Cost Board used in production workflows.
Operational alerting for AI spend anomalies with project-level ownership.
Monitor cost, tokens, usage, latency, errors, and request logs across providers in one platform.
This page is for engineering, platform, finance, and product teams evaluating AI API observability and cost-control workflows.
No. It covers cost together with usage, latency, errors, and request-level evidence so teams can make safer production decisions.
Yes. AI Cost Board combines dashboards, request logs, provider analytics, and budget controls for this use case.